









Hey everyone,
May 20, 2025 marked the opening session of Google I/O 2025, Google’s flagship event where they showcase the year’s biggest innovations. As we’ve seen over the past few years, artificial intelligence is no longer a future aspiration but a concrete, rapidly evolving reality—something we can’t ignore but need to learn how to use effectively.
In this article, we’ll explore the announcements from both opening sessions: the main Keynote and the Developer Keynote that followed (note that not everything is available yet—many features will roll out over the coming months).
Gemini 2.5: AI Gets Smarter (and Faster)
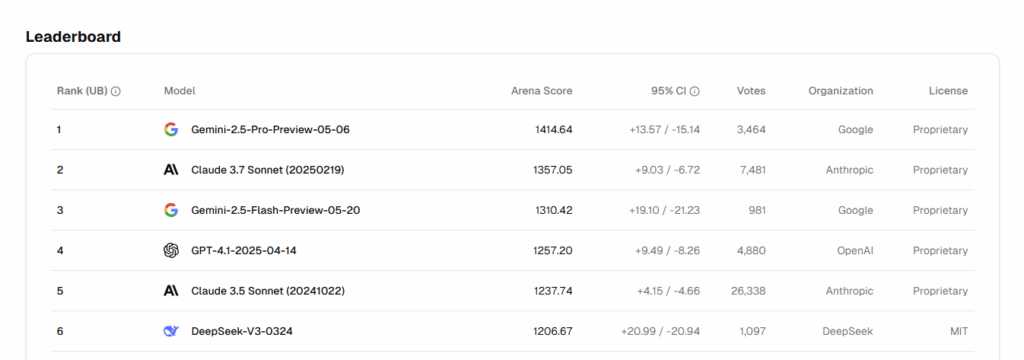
The undisputed star of the event was Gemini 2.5 Pro, described as “the most intelligent model.” This isn’t just marketing hype: Gemini 2.5 Pro topped every category in the prestigious LM Arena leaderboard and dominates the WebDev Arena for coding tasks.
I use AI extensively for learning and staying current with the latest trends, so I was particularly interested in the LearnLM integration, which makes Gemini 2.5 Pro incredibly effective in educational contexts.
For those seeking a balance between performance and efficiency, there’s Gemini Flash, which stands out for its speed and cost-effectiveness. The new 2.5 Flash version brings significant improvements across almost every aspect, particularly in reasoning, coding, and handling long contexts. We’ll get our hands on Flash in early June, with Pro following shortly after.
But the innovation doesn’t stop there—Google unveiled “Deep Think,” a new mode for Gemini 2.5 Pro that simulates reasoning, similar to what I’ve seen in Anthropic’s Claude. Using parallel processing techniques, Deep Think achieved impressive results on extremely complex benchmarks like the USA Math Olympics (where it placed second) and livecodebench. It’s currently being tested with select users.
Google’s AI Vision
Google’s vision extends beyond simple language models. The company is working to transform Gemini into a true “world model” (or should we call it AGI?), capable of planning and simulating aspects of the real world. This represents a major step toward what Google considers universal, personal, proactive, and powerful artificial intelligence (this motto was repeated across multiple slides during the presentation)—a milestone on the path to AGI. Who knows if this will be the first step toward Skynet—in which case, any of us could be John Connor!

Personalization and Privacy: Personal Context
Personalization is key to making AI truly useful in daily life. Google is developing the concept of “personal context,” where Gemini models can use information from a user’s Google apps privately, transparently, and with complete user control.
For example, Smart Reply in Gmail could respond more personally by drawing from notes in Google Drive. Users will control which information gets connected to the system.
In the Gemini app, users can already connect their search history and will soon be able to add more context from Drive and Gmail to make the assistant an extension of themselves. This level of personalization aims to create a proactive AI assistant that can anticipate needs and help users before they even ask.
Advanced APIs for Natural Interactions
The Live API (currently in preview) represents a qualitative leap in human-machine interaction, with a new native audio model 2.5 Flash that supports 24 languages and can distinguish between the main speaker and background voices.
Additionally, multimodal capabilities are central to the Gemini ecosystem: models can now use and understand text, images, video, and audio as input. Gemini 2.5 Flash, for example, has added audio understanding, becoming a truly multimodal model.
Simplified and Assisted Development
Google AI Studio,created to use Google’s models, has been completely redesigned and improved. The inclusion of a native code editor optimized for the SDKs allows rapid web application generation through prompts and previews of what’s generated.
Another tool that caught my interest is Stitch, an experimental project from Google Labs that lets you generate a design, modify it, then get the code or export the project to Figma.
For Android developers, Gemini is now integrated into Android Studio, automating repetitive tasks like refactoring, testing, and crash fixes. A particularly useful feature is the ability to write end-to-end tests using natural language (🤯).
On the horizon is also a feature that’ll help with dependency updates: it’ll analyze the project and update it while resolving any issues, right up to a successful build. This is interesting considering how many problems can emerge when updating libraries or dependencies.
Firebase Studio
Firebase Studio perhaps represents the clearest example of how AI is revolutionizing software development. This cloud-based AI workspace lets you create a fully functional application with a single prompt. The system can import designs from Figma and transform them into real code with Firebase Studio perhaps represents the clearest example of how AI is revolutionizing software development. This cloud-based AI workspace lets you create a fully functional application with a single prompt. The system can import designs from Figma and transform them into real code with Builder.io‘s help.
One of the announced features is adding a backend section to the App Blueprint: Firebase Studio can automatically detect the need for a backend (database, authentication, etc.) and generate all necessary code. Gemini in Firebase also helps build components, update routing logic, and manage data. It’s also great for architecture and project organization—during the presentation, we saw how it divided the application into functional components.

Google Search Reimagined with AI
Google’s search page is the most visited webpage in the world, but the world is changing. The presentation explained that search text has evolved from “brief and concise” to something more like a prompt. They introduced the new “AI mode”—search reinvented (powered by Gemini 2.5, of course)—which enables longer, more complex queries. This mode is gradually rolling out to all US users starting now.
Search Live: When AI Sees What You See
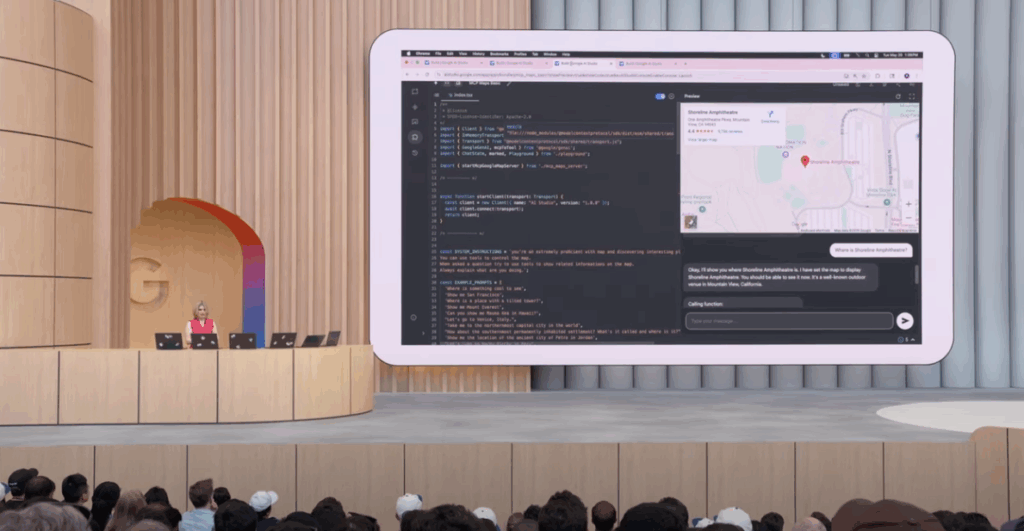
Several moments during the keynote really struck me, and one of the first showed video of a user walking while talking to Gemini and showing the world through their phone’s camera: the AI could understand context without falling into “traps,” like when asked who was following them while pointing the camera at their own shadow (here’s the moment I’m talking about).
All this was made possible through Search Live, which uses the camera to provide real-time information (similar to Google Lens, but happening in real-time).
Gemini App: The Increasingly Personal Assistant
The Gemini app is evolving into a universal, personal, proactive, and powerful AI assistant. Gemini Live, which now includes camera and screen sharing, is available free on Android and iOS. It’ll soon integrate with other Google apps like Calendar, Maps, Keep, and Tasks.

Project Starline and Google Beam: 3D Communication
They presented the Google Beam project, a new AI-powered video communication platform that transforms 2D video streaming into a realistic 3D experience using artificial intelligence and a 3D light field display. The first devices will be available to select customers by year’s end.
The underlying technology has also been integrated into Google Meet for real-time voice translation, now available for subscribers (English and Spanish, with more languages coming) and for businesses by year’s end.

Agentic Capabilities: AI Acting in the Real World
One aspect that really fuels my enthusiasm for AI is process automation to eliminate repetitive, boring tasks. Project Mariner was born in this space and can interact with the web and execute actions from a prompt. It’s made significant progress since its early days, including multitasking (up to 10 simultaneous tasks) and “teach and repeat” capability that lets the AI learn from examples.
Agentic capabilities are also coming to Chrome, Search, and the Gemini app. “Agent mode” in the app can find apartments, access real estate listings, and even plan visits while continuing to search for new listings in the background.
Android XR Glasses: Wearable AI
When I saw Shahram Izadi take the stage, I immediately knew those weren’t normal glasses: Google presented Android XR, an operating system with AI superpowers for smart glasses and headsets. Prototypes are being tested, and developers will be able to start designing applications for these devices by year’s end.
One of the most interesting live demos of the entire Keynote happened during this session, showing the glasses’ potential. The demo didn’t end as planned because Shahram Izadi’s glasses froze, but I think it was still a huge success. The most incredible aspects seen during the demo were definitely the Google Maps directions visualization and real-time translation with subtitles while two users spoke different languages. Google was already a pioneer in this technology with the Google Glass project, which (unfortunately) didn’t take off, but now the timing is definitely right and this type of technology is slowly gaining traction in people’s lives.


Creative Tools: Music, Video, and Content Protection
Speaking of creativity, several projects related to music, video, and images were presented.
Lyria 2, a high-fidelity generative music model, is now available for businesses, YouTube creators, and musicians.
Imagine 4, the latest model for image generation, produces richer, more detailed results with dramatically improved text and typography handling. There’s also a variant that’s 10 times faster.
Veo 3, the new state-of-the-art video generation model, improves visual quality and physics understanding while adding native audio generation, including sound effects, background sounds, and dialogue. The video of a fisherman talking from the edge of his boat, with ocean sounds as background, was very compelling.
Flow, a new AI-based filmmaking tool, combines the best of Vio, Imagine, and Gemini. It lets you upload images, generate new ones on the fly, assemble clips with text prompts and precise camera controls, while maintaining character and scene consistency.
To protect content authenticity, Synth ID integrates invisible watermarks into generated media (images, audio, text, video) for identification. A new detector makes it easier to identify content containing a Synth ID watermark. I recommend watching the moment when Flow is presented because the innovation becomes truly tangible (here’s the video).

AI for Science and Society
Google DeepMind is working to make AI available to researchers in various fields. The presentation mentioned several projects, including one dedicated to mathematics (Alpha Proof, which won a silver medal at the Math Olympics), advanced algorithms (Alpha Evolve), and biology (Amy, Alphafold 3).
AI is also being deployed to address social problems like fire detection through image analysis by satellites yet to be launched (Project Firesat) and humanitarian aid delivery, with Wing collaborating with Walmart and the Red Cross.
Finally, they mentioned some open models from the Gemma series, including MedGemma (specific to medical applications), SignGemma (American Sign Language), and even DolphinGemma, a model trained to understand dolphin vocalizations. 🐬

Wrapping Up
Google’s vision is clear: AI will become increasingly part of our daily reality, accelerate scientific discovery, and bring innovations that until recently seemed like pure science fiction.
With increasingly powerful and accessible tools for both developers and end users, we’re witnessing a profound transformation in how we interact with technology. The gap between what we imagine and what we can achieve is shrinking at a surprising pace, opening possibilities that were unimaginable just a few years ago.
Watching this event made me realize what the future holds for us—a time when our capabilities will be extended by increasingly smart devices and increasingly personal assistants.


