








Ciao a tutti,
il 20 maggio 2025 si è svolta la sessione di apertura di Google I/O 2025, l’evento di casa G dove vengono presentate tutte le novità dell’anno. Come da qualche anno a questa parte l’intelligenza artificiale non è più un’aspirazione futura ma una realtà concreta ed in rapida evoluzione, un qualcosa a cui non possiamo sottrarci ma bensì che dobbiamo imparare ad utilizzare.
Nel corso di questo articolo vedremo insieme le novità presentate durante le due sessioni di apertura, il Keynote di apertura e il successivo Developer Keynote (da notare che non tutto è già disponibile, molte cose saranno rilasciate nel corso dei prossimi mesi).
Gemini 2.5: l’AI diventa più intelligente (e più veloce)
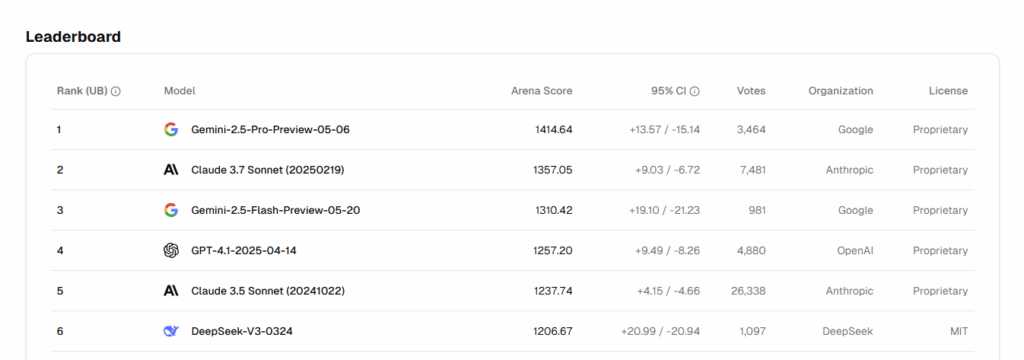
Il protagonista indiscusso dell’evento è stato Gemini 2.5 Pro, descritto come “il modello più intelligente”. Non è solo un’affermazione di marketing: Gemini 2.5 Pro ha conquistato il primo posto in tutte le categorie nella prestigiosa classifica LM Arena e domina la WebDev Arena per quanto riguarda il coding.
Io utilizzo molto l’AI per studiare e per rimanere aggiornato sugli ultimi trend, mi è quindi parso molto interessante l’integrazione di LearnLM, che rende Gemini 2.5 Pro molto performante nel settore educativo.
Per chi cerca un compromesso tra prestazioni ed efficienza ecco a voi Gemini Flash che si contraddistingue per la sua velocità ed i costi contenuti. La nuova versione 2.5 Flash porta miglioramenti significativi in quasi ogni aspetto, in particolare nel ragionamento, nel codice e nella gestione di contesti lunghi. Potremo mettere le mani su Flash all’inizio di giugno, con Pro che seguirà subito dopo.
Ma l’innovazione non si ferma qui perché big G ha presentato “Deep Think”, una nuova modalità per Gemini 2.5 Pro che simula un ragionamento, simile a quanto già ho visto in Claude di Anthropic. Utilizzando tecniche di elaborazione parallela, Deep Think ha ottenuto risultati impressionanti su benchmark estremamente complessi come le Olimpiadi di Matematica USA (dove è arrivata seconda) e livecodebench. Attualmente è in fase di test con utenti selezionati.
La visione dell’AI di Google
La visione di Google va oltre i semplici modelli linguistici. L’azienda sta lavorando per trasformare Gemini in un vero e proprio “world model” (o meglio chiamarlo AGI?), capace di pianificare e simulare aspetti del mondo reale. Questo rappresenta un passo importante verso quella che Google considera un’intelligenza artificiale universale, personale, proattiva e potente (questo è il motto ripetuto in più di una slide durante la presentazione) – una pietra miliare nel cammino verso l’AGI (Artificial General Intelligence). Chissà se sarà il primo passo verso Skynet, in tal caso ognuno di noi potrebbe essere John Connor!

Personalizzazione e privacy: il contesto personale
La personalizzazione rappresenta un elemento chiave per rendere l’AI veramente utile nella vita quotidiana. Google sta sviluppando il concetto di “contesto personale”, dove i modelli Gemini possono utilizzare informazioni dalle app Google dell’utente in modo privato, trasparente e completamente controllabile.
Ad esempio, le risposte Smart Reply in Gmail potrebbero rispondere in modo più personale attingendo dalle note presenti in Google Drive. L’utente potrà gestire quali informazioni vengono collegate al sistema.
Nell’app Gemini, l’utente può già collegare la cronologia di ricerca e presto potrà aggiungere altro contesto da Drive e Gmail per rendere l’assistente un’estensione di se stesso. Questo livello di personalizzazione mira a creare un assistente AI proattivo, capace di anticipare le esigenze e aiutare l’utente anche prima che venga formulata una richiesta.
API evolute per interazioni naturali
La Live API (attualmente in preview) rappresenta un salto qualitativo nell’interazione uomo-macchina, con un nuovo modello audio nativo 2.5 Flash che supporta 24 lingue e può distinguere tra l’interlocutore principale e le voci di sottofondo.
Inoltre le capacità multimodali sono al centro dell’ecosistema Gemini: i modelli possono ora utilizzare e comprendere testo, immagini, video e audio come input. Gemini 2.5 Flash, ad esempio, ha aggiunto la comprensione dell’audio, diventando un modello veramente multimodale.
Sviluppo semplificato e assistito
Google AI Studio, nato per poter utilizzare i modelli di Google, è stato completamente ripensato e migliorato. L’inclusione di un editor di codice nativo ottimizzato per gli SDK permette di generare rapidamente applicazioni web tramite prompt e preview di quanto generato.
Un altro strumento che ha solleticato il mio interesse è Stitch, un progetto sperimentale di Google Labs che consente di generare un design, modificarlo per poi ottenere il codice o esportare il progetto in Figma.
Per gli sviluppatori Android, Gemini è ora integrato in Android Studio, automatizzando compiti ripetitivi come refactoring, testing e correzione dei crash. Una funzionalità particolarmente utile è la possibilità di scrivere test end-to-end usando il linguaggio naturale (🤯).
All’orizzonte c’è anche una funzionalità che ci aiuterà con gli aggiornamenti delle dipendenze: analizzerà il progetto e lo aggiornerà risolvendo eventuali problemi, fino al successo della build. Aspetto interessante considerato quanti problemi possono emergere durante l’aggiornamento di librerie o dipendenze.
Firebase Studio
Firebase Studio rappresenta forse l’esempio più evidente di come l’AI stia rivoluzionando lo sviluppo software. Questo workspace AI basato su cloud permette di creare un’applicazione completamente funzionale con un singolo prompt. Il sistema può importare design da Figma per poi trasformarlo in codice reale con l’aiuto di Builder.io.
Una delle novità presentate è l’aggiunta di una sezione backend all’App Blueprint: Firebase Studio può rilevare automaticamente la necessità di un backend (database, autenticazione,..) generando tutto il codice necessario. Gemini in Firebase aiuta anche a costruire componenti, aggiornare la logica di routing e gestire i dati. Ottimo anche per quanto riguarda l’architettura e l’organizzazione del progetto, durante la presentazione si è visto come ha suddiviso l’applicazione in componenti funzionali.

Google Search ripensata con l’AI
La pagina di ricerca di Google è la pagina web più visitata al mondo, ma il mondo sta cambiando. Nella presentazione è stato spiegato che il testo di ricerca è passato da un testo “breve e conciso” ad un testo di ricerca più simile ad un prompt. È stata quindi presentata la nuova modalità “AI mode”, la ricerca re-inventata (sotto al cofano troviamo ovviamente Gemini 2.5), che consente query più lunghe e complesse. Questa modalità sta venendo gradualmente estesa a tutti gli utenti negli Stati Uniti a partire da ora.
Search Live: quando l’AI vede ciò che vedi tu
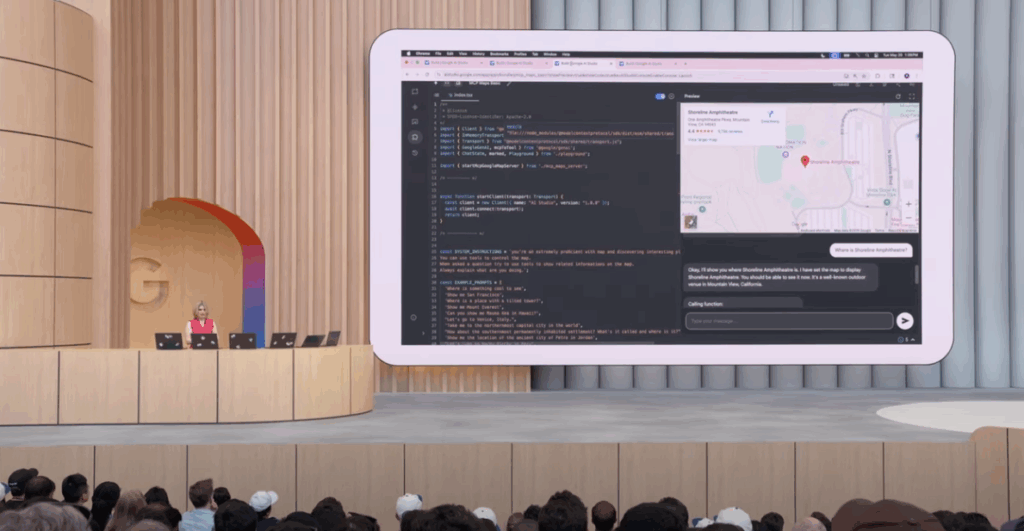
Ci sono diversi momenti durante il keynote che mi hanno colpito molto, uno di questi primo mostrava il video di un’utente che passeggiava mentre parlava con Gemini e mostrava il mondo attraverso la fotocamera del telefono: l’AI era in grado di capire il contesto senza cadere in “trappola”, come quando gli è stato chiesto chi la stava seguendo mentre inquadrava con il telefono la propria ombra (qui il momento di cui vi sto parlando).
Tutto questo è stato reso possibile tramite Search Live, che tramite la fotocamera può fornire informazioni in tempo reale (come già accade con Google Lens, con la differenza che qui avviene tutto in tempo reale).
Gemini App: l’assistente sempre più personale
L’app Gemini sta evolvendo verso un assistente AI universale, personale, proattivo e potente. Gemini Live, che ora include la condivisione della fotocamera e dello schermo, è disponibile gratuitamente su Android e iOS. Presto si integrerà con altre app Google come Calendar, Maps, Keep e Tasks.

Project Starline e Google Beam: comunicazione 3D
E’ stato presentato il progetto Google Beam, una nuova piattaforma di comunicazione video basata sull’AI che trasforma streaming video 2D in un’esperienza 3D realistica, utilizzando l’intelligenza artificiale e un display 3D light field. I primi dispositivi saranno disponibili per i clienti selezionati entro la fine dell’anno.
La tecnologia sottostante è stata integrata anche in Google Meet per la traduzione vocale in tempo reale, ora disponibile per gli abbonati (inglese e spagnolo, con altre lingue in arrivo) e per le aziende entro la fine dell’anno.

Capacità Agentiche: AI che agisce nel mondo reale
Uno degli aspetti che alimenta molto il mio entusiasmo verso l’AI è legato all’automatizzazione dei processi per eliminare task ripetitivi e noiosi. Project Mariner nasce proprio in questo ambito e può interagire con il web ed eseguire azioni partendo da un prompt. Rispetto agli esordi ha fatto progressi significativi, incluso il multitasking (fino a 10 compiti simultanei) e la capacità “teach and repeat” che permette all’AI di imparare partendo da un esempio.
Le capacità agentiche stanno arrivando anche a Chrome, Search e all’app Gemini. La “modalità agente” nell’app può trovare appartamenti, accedere a elenchi immobiliari e persino pianificare visite, continuando a cercare nuovi annunci in background.
Android XR glasses: l’AI indossabile
Quando ho visto Shahram Lzadi salire sul palco ho capito subito che quelli che indossava non erano occhiali normali: Google ha presentato Android XR, un sistema operativo con i superpoteri dell’AI per occhiali smart e headset. I prototipi sono in fase di test e gli sviluppatori potranno iniziare a progettare applicazioni per questi dispositivi entro la fine dell’anno.
Durante la sessione è anche stata fatta una delle demo live più interessanti di tutto il Keynote, mostrando le potenzialità degli occhiali. La demo non si è conclusa come prevsito, poichè l’occhiale di Shahram Lzadi si è freezato, ma è stato a mio avviso un enorme successo. Gli aspetti più incredibili visti durante la demo sono sicuramente la visualizzazione delle indicazioni di Google maps e la traduzione in simultanea con sottotitoli mentre due utenti parlano lingue differenti. Google è già stata pioniera di questa tecnologia con il progetto Google Glass, progetto (purtroppo) non decollato, ma ora i tempi sono sicuramente maturi e questo tipo di tecnologia sta lentamente prendendo piede nelle vite delle persone.


Strumenti per i creativi: musica, video e protezione dei contenuti
Parlando di creatività sono stati presentati diversi progetti legati a musica, video ed immagini.
Lyria 2, un modello generativo di musica ad alta fedeltà, è ora disponibile per aziende, YouTube creator e musicisti.
Imagine 4, il modello più recente per la generazione di immagini, produce risultati più ricchi e dettagliati, migliorando drasticamente la gestione del testo e della tipografia. È disponibile anche una variante 10 volte più veloce.
Veo 3, il nuovo modello all’avanguardia per la generazione video, migliora la qualità visiva e la comprensione della fisica, aggiungendo anche la generazione audio nativa, inclusi effetti sonori, suoni di sottofondo e dialoghi. Molto suggestivo il video di un pescatore che parla dal bordo della sua barca, con i suoni del mare come sottofondo.
Flow, un nuovo strumento di filmmaking basato sull’AI, combina il meglio di Vio, Imagine e Gemini. Permette di caricare immagini, generarne di nuove al volo, assemblare clip con prompt testuali e controlli precisi della telecamera, mantenendo la coerenza dei personaggi e delle scene.
Per proteggere l’autenticità dei contenuti, Synth ID integra filigrane invisibili nei media generati (immagini, audio, testo, video) per l’identificazione. Un nuovo detector facilita l’identificazione dei contenuti che contengono un watermark Synth ID. Vi consiglio di guardare il momento in cui viene presentato flow poiché l’innovazione diventa veramente tangibile (qui il video)

AI per la scienza e la società
Google DeepMind sta lavorando affinchè l’AI sia a disposizione dei ricercatori di vari ambiti. Nella presentazione sono stati accennati alcuni progetti, tra cui quello dedicato alla matematica (Alpha Proof, che ha vinto una medaglia d’argento alle olimpiadi di matematica), agli algoritmi avanzati (Alpha Evolve) e alla biologia (Amy, Alphafold 3).
L’AI viene impiegata anche per affrontare problemi sociali come l’individuazione degli incendi tramite l’analisi delle immagini effettuata da alcuni satelliti che devono ancora essere lanciati (Project Firesat) e la consegna di aiuti umanitari, con Wing che collabora con Walmart e Croce Rossa.
Infine sono stati citati alcuni modelli aperti della serie Gemma, tra cui MedGemma (specifico per l’ambito medicale), SignGemma (lingua dei segni americana) e persino DolphinGemma, un modello addestrato per comprendere le vocalizzazioni dei delfini. 🐬

Conclusioni
La visione di Google è chiara: l’IA diventerà sempre più parte della nostra realtà quotidiana, accelererà la scoperta scientifica e portarà innovazioni che fino a poco tempo fa sembravano pura fantascienza.
Con strumenti sempre più potenti e accessibili, sia per gli sviluppatori che per gli utenti finali, stiamo assistendo a una trasformazione profonda del modo in cui interagiamo con la tecnologia. La distanza tra ciò che immaginiamo e ciò che possiamo realizzare si sta riducendo a una velocità sorprendente, aprendo possibilità che fino a pochi anni fa erano inimmaginabili.
Guardando questo evento mi sono reso conto di quale sarà il futuro che ci attende, un tempo dove le nostre capacità saranno estese da dispositivi sempre più smart e da assistenti sempre più personali.


