






Il 5 Agosto 2025 OpenAI ha annunciato di aver rilasciato due nuovi modelli (gpt-oss-120b e gpt-oss-20b), i primi modelli linguistici open-weight dell’azienda dal lancio di GPT-2 (correva l’anno 2019). Questi due modelli rappresentano un punto di svolta significativo nel panorama dell’intelligenza artificiale, offrendo capacità di ragionamento avanzate e prestazioni competitive con i modelli proprietari, il tutto sotto licenza Apache 2.0.
Questa mossa si inserisce in un contesto dove i modelli open iniziano a fare sempre più la loro comparsa, aprendo nuovi scenari di utilizzo e di personalizzazione (pensiamo anche solo a contesti dove il modello deve essere eseguito in locale per questioni di privacy o sicurezza).
Architettura e prestazioni
I modelli GPT-OSS utilizzano un’architettura Mixture-of-Experts (MoE – un’architettura che divide un modello AI in tanti “esperti” specializzati, ma attiva solo alcuni di essi per ogni input) che li rende estremamente efficienti. Il gpt-oss-120b attiva solo 5,1 miliardi di parametri per token su un totale di 117 miliardi, mentre il gpt-oss-20b ne attiva 3,6 miliardi su 21 miliardi totali. Questa architettura permette al modello più grande di funzionare su una singola GPU da 80GB, mentre quello più piccolo richiede solo 16GB di memoria. Pazzesco. 16 è davvero un bel traguardo.
Le prestazioni sono impressionanti: gpt-oss-120b raggiunge risultati quasi equivalenti a OpenAI o4-mini nei principali benchmark di ragionamento, mentre gpt-oss-20b si avvicina alle prestazioni di o3-mini nonostante sia sei volte più piccolo. Entrambi i modelli eccellono particolarmente in matematica competitiva, dove possono utilizzare catene di ragionamento molto lunghe (oltre 20.000 token per problema).
Ragionamento variabile
Una delle caratteristiche più innovative è il ragionamento a sforzo variabile. I modelli supportano tre livelli di ragionamento (basso, medio, alto) configurabili tramite prompt di sistema, permettendo agli sviluppatori di bilanciare prestazioni, latenza e costi in base alle necessità specifiche. Questa flessibilità li rende ideali per applicazioni che richiedono diversi gradi di complessità computazionale.
Capacità agentiche
I modelli sono stati progettati specificamente per flussi di lavoro agentici, supportando nativamente:
- Navigazione web per ricerche e accesso a informazioni aggiornate
- Esecuzione di codice Python in ambiente Jupyter
- Function calling per l’integrazione con sistemi esterni
- Output strutturati per applicazioni enterprise
Queste capacità li rendono particolarmente adatti per applicazioni che richiedono interazione con l’ambiente esterno e automazione complessa. Non so voi ma ho già in mente circa 250 possibili progetti 🙂
Sicurezza
OpenAI ha sottoposto i modelli a test di “adversarial fine-tuning” da parte di 3 gruppi indipendenti per verificare che i modelli non possano essere facilmente compromessi per scopi illeciti o fraudolenti. Secondo l’articolo pubblicato da OpanAI, i risultati dei test hanno dimostrato che l’utilizzo di questi modelli con finalità malevoli è contenuta.
Chain of Thought
Per quanto riguarda le strategie di addestramento, è stato utilizzato un approccio non supervisionato alla catena di ragionamento (CoT) verso i comportamenti anomali (es. non sempre il modello rispetta eventuali vincoli forniti nel prompt).
Tuttavia, questa scelta comporta la responsabilità per gli sviluppatori di filtrare appropriatamente i contenuti della risposta prima di mostrarli agli utenti finali, poiché possono contenere linguaggio non allineato alle policy di sicurezza standard (i modelli commerciali invece hanno una catena di ragionamento supervisionata).
Vantaggi
Il rilascio open-weight offre vantaggi significativi:
- Personalizzazione completa attraverso fine-tuning
- Controllo totale sui dati e l’infrastruttura
- Costi ridotti per deployment locale
- Accessibilità per mercati emergenti e organizzazioni con budget limitati
- Trasparenza nell’implementazione e nei processi decisionali
Svantaggi e limitazioni
Nonostante i notevoli punti di forza, esistono alcune limitazioni:
- Performance inferiori rispetto ai modelli proprietari più avanzati in alcuni benchmark
- Responsabilità di sicurezza maggiore per gli sviluppatori (es. controllo dei prompt prima di ritornarli all’utente)
- Mancanza di supporto multimodale (solo testo)
- Rischio di allucinazioni più elevato rispetto a modelli più grandi
- Complessità di deployment che richiede competenze tecniche specifiche
Licenza
I due modelli sono rilasciati sotto la licenza “Apache 2.0”, una delle più usate nel mondo open source. Potremo quindi utilizzare questi modelli, modificarli e distribuirli sia per scopi personali che commerciali.
GPT-OSS vs i competitor “Open”
Nonostante quanto fatto da OpenAI sia un passo notevole e che accogliamo con grande entusiasmo, esso si inserisce in un contesto dove i modelli Open già esistono. Tutto è iniziato forse con DeepSeek ed ha continuato fino ad arrivare al modello di Qwen, rilasciato qualche mese fa con grande entusiasmo da parte del pubblico.
Nel mondo dell’informatica l’open source è un motore in grado di smuovere l’umanità, ogni nuovo modello “Open” è un passo in avanti verso un’IA sempre più accessibile a prezzi contenuti .
Nei prossimi giorni appariranno sicuramente dei benchmark più specifici sui confronti con altri modelli e vedremo se saranno veramente modelli all’altezza delle aspettative, in grado di superare gli altri modelli, nel frattempo possiamo trovare uno dei primi benchmark del modello a questo repo Github (https://github.com/johnbean393/SVGBench). Il benchmark in questione confronta i modelli in funzione di conoscenza, sviluppo seguire le istruzioni e ragionamento fisico.
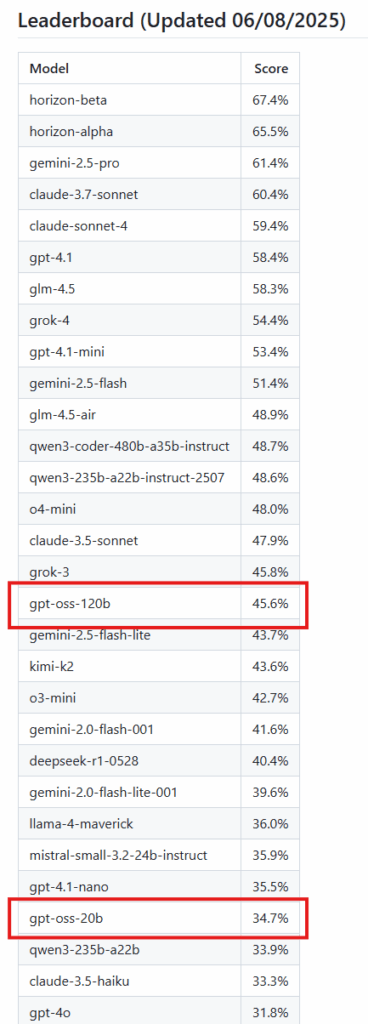
ATTENZIONE Come ben sappiamo un modello può “performare” in un ambito ma essere scarso in un altro, ad oggi non esiste il modello perfetto per qualsiasi contesto. Come sviluppatori dobbiamo essere in grado di utilizzare il modello giusto in funzione di quello che ci serve, inserito magari in un’applicazione RAG.
Fonti per l’approfondimento
Vi lascio il link a due articoli: il primo è l’articolo sul sito di OpenAI con l’annuncio di questi modelli, il secondo è il paper con i dettagli più tecnici dei modelli.
Se vuoi provare i modelli invece, puoi andare qui: https://gpt-oss.com/
Conclusioni
Il rilascio dei modelli GPT-OSS segna il ritorno di OpenAI nel mondo open-source dopo sei anni, dimostrando che prestazioni competitive e accessibilità possono coesistere. Gli aspetti più interessanti sono sicuramente la licenza, le capacità agentiche ed il tema della memoria, con il modello 20b che ne richiede “solo” 16GB, aprendo la possibilità di utilizzarlo anche in contesti domestici.
La scelta di mantenere non censurata la catena di ragionamento sposta la responsabilità della sicurezza agli sviluppatori, aprendo nuove opportunità ma richiedendo maggiore maturità tecnica da parte di chi implementerà ed utilizzerà questi modelli.
GPT-OSS si inserisce in un ecosistema open-source sempre più competitivo, dove la filosofia multi-modello diventa essenziale: non esiste il modello perfetto, ma quello giusto per ogni contesto specifico. Il vero valore risiede nell’integrazione in architetture più ampie e nelle capacità agentiche native. Questo rilascio rappresenta un segnale chiaro verso un futuro dove l’AI sarà sempre più “open”, trasparente e democratico. Mentre aspettiamo i benchark dei modelli non mi rimane che augurarvi un buon proseguimento, al prossimo articolo!